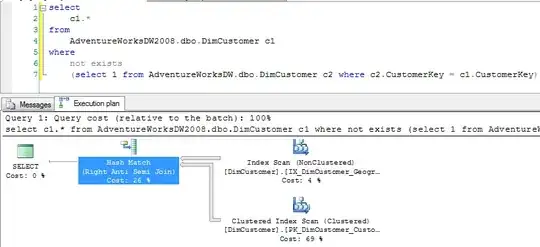
I have a 1:1 relationship between two tables. I want to find all the rows in table A that don't have a corresponding row in table B. I use this query:
SELECT id
FROM tableA
WHERE id NOT IN (SELECT id
FROM tableB)
ORDER BY id desc
id is the primary key in both tables. Apart from primary key indices, I also have a index on tableA(id desc).
Using H2 (Java embedded database), this results in a full table scan of tableB. I want to avoid a full table scan.
How can I rewrite this query to run quickly? What index should I should?