You should prefer the JPA methods most of the time, and the update for batch processing tasks.
A JPA or Hibernate entity can be in one of the following four states:
- Transient (New)
- Managed (Persistent)
- Detached
- Removed (Deleted)
The transition from one state to the other is done via the EntityManager or Session methods.
For instance, the JPA EntityManager provides the following entity state transition methods.
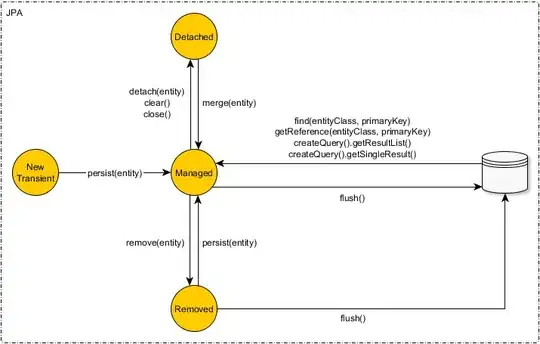
The Hibernate Session implements all the JPA EntityManager methods and provides some additional entity state transition methods like save, saveOrUpdate and update.

Persist
To change the state of an entity from Transient (New) to Managed (Persisted), we can use the persist method offered by the JPA EntityManager which is also inherited by the Hibernate Session.
The persist method triggers a PersistEvent which is handled by the DefaultPersistEventListener Hibernate event listener.
Therefore, when executing the following test case:
doInJPA(entityManager -> {
Book book = new Book()
.setIsbn("978-9730228236")
.setTitle("High-Performance Java Persistence")
.setAuthor("Vlad Mihalcea");
entityManager.persist(book);
LOGGER.info(
"Persisting the Book entity with the id: {}",
book.getId()
);
});
Hibernate generates the following SQL statements:
CALL NEXT VALUE FOR hibernate_sequence
-- Persisting the Book entity with the id: 1
INSERT INTO book (
author,
isbn,
title,
id
)
VALUES (
'Vlad Mihalcea',
'978-9730228236',
'High-Performance Java Persistence',
1
)
Notice that the id is assigned prior to attaching the Book entity to the current Persistence Context. This is needed because the managed entities are stored in a Map structure where the key is formed by the entity type and its identifier and the value is the entity reference. This is the reason why the JPA EntityManager and the Hibernate Session are known as the First-Level Cache.
When calling persist, the entity is only attached to the currently running Persistence Context, and the INSERT can be postponed until the flush is called.
The only exception is the IDENTITY which triggers the INSERT right away since that's the only way it can get the entity identifier. For this reason, Hibernate cannot batch inserts for entities using the IDENTITY generator.
Save
The Hibernate-specific save method predates JPA and it's been available since the beginning of the Hibernate project.
The save method triggers a SaveOrUpdateEvent which is handled by the DefaultSaveOrUpdateEventListener Hibernate event listener. Therefore, the save method is equivalent to the update and saveOrUpdate methods.
To see how the save method works, consider the following test case:
doInJPA(entityManager -> {
Book book = new Book()
.setIsbn("978-9730228236")
.setTitle("High-Performance Java Persistence")
.setAuthor("Vlad Mihalcea");
Session session = entityManager.unwrap(Session.class);
Long id = (Long) session.save(book);
LOGGER.info(
"Saving the Book entity with the id: {}",
id
);
});
When running the test case above, Hibernate generates the following SQL statements:
CALL NEXT VALUE FOR hibernate_sequence
-- Saving the Book entity with the id: 1
INSERT INTO book (
author,
isbn,
title,
id
)
VALUES (
'Vlad Mihalcea',
'978-9730228236',
'High-Performance Java Persistence',
1
)
As you can see, the outcome is identical to the persist method call. However, unlike persist, the save method returns the entity identifier.
Update
The Hibernate-specific update method is meant to bypass the dirty checking mechanism and force an entity update at the flush time.
The update method triggers a SaveOrUpdateEvent which is handled by the DefaultSaveOrUpdateEventListener Hibernate event listener. Therefore, the update method is equivalent to the save and saveOrUpdate methods.
To see how the update method works consider the following example which persists a Book entity in one transaction, then it modifies it while the entity is in the detached state, and it forces the SQL UPDATE using the update method call.
Book _book = doInJPA(entityManager -> {
Book book = new Book()
.setIsbn("978-9730228236")
.setTitle("High-Performance Java Persistence")
.setAuthor("Vlad Mihalcea");
entityManager.persist(book);
return book;
});
LOGGER.info("Modifying the Book entity");
_book.setTitle(
"High-Performance Java Persistence, 2nd edition"
);
doInJPA(entityManager -> {
Session session = entityManager.unwrap(Session.class);
session.update(_book);
LOGGER.info("Updating the Book entity");
});
When executing the test case above, Hibernate generates the following SQL statements:
CALL NEXT VALUE FOR hibernate_sequence
INSERT INTO book (
author,
isbn,
title,
id
)
VALUES (
'Vlad Mihalcea',
'978-9730228236',
'High-Performance Java Persistence',
1
)
-- Modifying the Book entity
-- Updating the Book entity
UPDATE
book
SET
author = 'Vlad Mihalcea',
isbn = '978-9730228236',
title = 'High-Performance Java Persistence, 2nd edition'
WHERE
id = 1
Notice that the UPDATE is executed during the Persistence Context flush, right before commit, and that's why the Updating the Book entity message is logged first.
Using @SelectBeforeUpdate to avoid unnecessary updates
Now, the UPDATE is always going to be executed even if the entity was not changed while in the detached state. To prevent this, you can use the @SelectBeforeUpdate Hibernate annotation which will trigger a SELECT statement that fetched loaded state which is then used by the dirty checking mechanism.
So, if we annotate the Book entity with the @SelectBeforeUpdate annotation:
@Entity(name = "Book")
@Table(name = "book")
@SelectBeforeUpdate
public class Book {
//Code omitted for brevity
}
And execute the following test case:
Book _book = doInJPA(entityManager -> {
Book book = new Book()
.setIsbn("978-9730228236")
.setTitle("High-Performance Java Persistence")
.setAuthor("Vlad Mihalcea");
entityManager.persist(book);
return book;
});
doInJPA(entityManager -> {
Session session = entityManager.unwrap(Session.class);
session.update(_book);
});
Hibernate executes the following SQL statements:
INSERT INTO book (
author,
isbn,
title,
id
)
VALUES (
'Vlad Mihalcea',
'978-9730228236',
'High-Performance Java Persistence',
1
)
SELECT
b.id,
b.author AS author2_0_,
b.isbn AS isbn3_0_,
b.title AS title4_0_
FROM
book b
WHERE
b.id = 1
Notice that, this time, there is no UPDATE executed since the Hibernate dirty checking mechanism has detected that the entity was not modified.
SaveOrUpdate
The Hibernate-specific saveOrUpdate method is just an alias for save and update.
The saveOrUpdate method triggers a SaveOrUpdateEvent which is handled by the DefaultSaveOrUpdateEventListener Hibernate event listener. Therefore, the update method is equivalent to the save and saveOrUpdate methods.
Now, you can use saveOrUpdate when you want to persist an entity or to force an UPDATE as illustrated by the following example.
Book _book = doInJPA(entityManager -> {
Book book = new Book()
.setIsbn("978-9730228236")
.setTitle("High-Performance Java Persistence")
.setAuthor("Vlad Mihalcea");
Session session = entityManager.unwrap(Session.class);
session.saveOrUpdate(book);
return book;
});
_book.setTitle("High-Performance Java Persistence, 2nd edition");
doInJPA(entityManager -> {
Session session = entityManager.unwrap(Session.class);
session.saveOrUpdate(_book);
});
Beware of the NonUniqueObjectException
One problem that can occur with save, update, and saveOrUpdate is if the Persistence Context already contains an entity reference with the same id and of the same type as in the following example:
Book _book = doInJPA(entityManager -> {
Book book = new Book()
.setIsbn("978-9730228236")
.setTitle("High-Performance Java Persistence")
.setAuthor("Vlad Mihalcea");
Session session = entityManager.unwrap(Session.class);
session.saveOrUpdate(book);
return book;
});
_book.setTitle(
"High-Performance Java Persistence, 2nd edition"
);
try {
doInJPA(entityManager -> {
Book book = entityManager.find(
Book.class,
_book.getId()
);
Session session = entityManager.unwrap(Session.class);
session.saveOrUpdate(_book);
});
} catch (NonUniqueObjectException e) {
LOGGER.error(
"The Persistence Context cannot hold " +
"two representations of the same entity",
e
);
}
Now, when executing the test case above, Hibernate is going to throw a NonUniqueObjectException because the second EntityManager already contains a Book entity with the same identifier as the one we pass to update, and the Persistence Context cannot hold two representations of the same entity.
org.hibernate.NonUniqueObjectException:
A different object with the same identifier value was already associated with the session : [com.vladmihalcea.book.hpjp.hibernate.pc.Book#1]
at org.hibernate.engine.internal.StatefulPersistenceContext.checkUniqueness(StatefulPersistenceContext.java:651)
at org.hibernate.event.internal.DefaultSaveOrUpdateEventListener.performUpdate(DefaultSaveOrUpdateEventListener.java:284)
at org.hibernate.event.internal.DefaultSaveOrUpdateEventListener.entityIsDetached(DefaultSaveOrUpdateEventListener.java:227)
at org.hibernate.event.internal.DefaultSaveOrUpdateEventListener.performSaveOrUpdate(DefaultSaveOrUpdateEventListener.java:92)
at org.hibernate.event.internal.DefaultSaveOrUpdateEventListener.onSaveOrUpdate(DefaultSaveOrUpdateEventListener.java:73)
at org.hibernate.internal.SessionImpl.fireSaveOrUpdate(SessionImpl.java:682)
at org.hibernate.internal.SessionImpl.saveOrUpdate(SessionImpl.java:674)
Merge
To avoid the NonUniqueObjectException, you need to use the merge method offered by the JPA EntityManager and inherited by the Hibernate Session as well.
The merge fetches a new entity snapshot from the database if there is no entity reference found in the Persistence Context, and it copies the state of the detached entity passed to the merge method.
The merge method triggers a MergeEvent which is handled by the DefaultMergeEventListener Hibernate event listener.
To see how the merge method works consider the following example which persists a Book entity in one transaction, then it modifies it while the entity is in the detached state, and passes the detached entity to merge in a subsequence Persistence Context.
Book _book = doInJPA(entityManager -> {
Book book = new Book()
.setIsbn("978-9730228236")
.setTitle("High-Performance Java Persistence")
.setAuthor("Vlad Mihalcea");
entityManager.persist(book);
return book;
});
LOGGER.info("Modifying the Book entity");
_book.setTitle(
"High-Performance Java Persistence, 2nd edition"
);
doInJPA(entityManager -> {
Book book = entityManager.merge(_book);
LOGGER.info("Merging the Book entity");
assertFalse(book == _book);
});
When running the test case above, Hibernate executed the following SQL statements:
INSERT INTO book (
author,
isbn,
title,
id
)
VALUES (
'Vlad Mihalcea',
'978-9730228236',
'High-Performance Java Persistence',
1
)
-- Modifying the Book entity
SELECT
b.id,
b.author AS author2_0_,
b.isbn AS isbn3_0_,
b.title AS title4_0_
FROM
book b
WHERE
b.id = 1
-- Merging the Book entity
UPDATE
book
SET
author = 'Vlad Mihalcea',
isbn = '978-9730228236',
title = 'High-Performance Java Persistence, 2nd edition'
WHERE
id = 1
Notice that the entity reference returned by merge is different than the detached one we passed to the merge method.
Now, although you should prefer using JPA merge when copying the detached entity state, the extra SELECT can be problematic when executing a batch processing task.
For this reason, you should prefer using update when you are sure that there is no entity reference already attached to the currently running Persistence Context and that the detached entity has been modified.
Conclusion
To persist an entity, you should use the JPA persist method. To copy the detached entity state, merge should be preferred. The update method is useful for batch processing tasks only. The save and saveOrUpdate are just aliases to update and you should not probably use them at all.
Some developers call save even when the entity is already managed, but this is a mistake and triggers a redundant event since, for managed entities, the UPDATE is automatically handled at the Persistence context flush time.