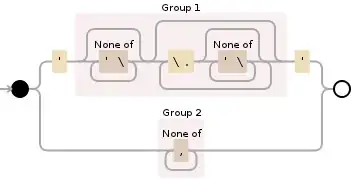
This is how I would go about solving this:
('(?>\\.|.)*?'|[^\,]+)
Regex101
Explanation:
( Start capture group
' Match an apostrophe
(?> Atomically match the following
\\. Match \ literally and then any single character
|. Or match just any single character
) Close atomic group
*?' Match previous group 0 or more times until the first '
|[^\,] OR match any character that is not a comma (,)
+ Match the previous regex [^\,] one or more times
) Close capture group
A note about how the atomic group works:
Say I had this string 'a \' b'
The atomic group (?>\\.|.) will match this string in the following way at each step:
'a\'b'
If the match ever fails in the future, it will not attempt to match \' as \, ' but will always match/use the first option if it fits.
If you need help escaping the regex, here's the escaped version: ('(?>\\\\.|.)*?'|[^\\,]+)
although i spent about 10 hours writing regex yesterday, i'm not too experienced with it. i've researched escaping backslashes but was confused by what i read. what's your reason for not escaping in your original answer? does it depend on different languages/platforms? ~OP
Section on why you have to escape regex in programming languages.
When you write the following string:
"This is on one line.\nThis is on another line."
Your program will interpret the \n literally and see it the following way:
"This is on one line.
This is on another line."
In a regular expression, this can cause a problem. Say you wanted to match all characters that were not line breaks. This is how you would do that:
"[^\n]*"
However, the \n is interpreted literally when written in a programming language and will be seen the following way:
"[^
]*"
Which, I'm sure you can tell, is wrong. So to fix this we escape strings. By placing a backslash in front of the first backslash when can tell the programming language to look at \n differently (or any other escape sequence: \r, \t, \\, etc). On a basic level, escape trade the original escape sequence \n for another escape sequence and then a character \\, n. This is how escaping affects the regex above.
"[^\\n]*"
The way the programming language will see this is the following:
"[^\n]*"
This is because \\ is an escape sequence that means "When you see \\ interpret it literally as \". Because \\ has already been consumed and interpreted, the next character to read is n and therefore is no longer part of the escape sequence.
So why do I have 4 backslashes in my escaped version? Let's take a look:
(?>\\.|.)
So this is the original regex we wrote. We have two consecutive backslashes. This section (\\.) of the regular expression means "Whenever you see a backslash and then any character, match". To preserve this interpretation for the regex engine, we have to escape each, individual backslash.
\\ \\ .
So all together it looks like this:
(?>\\\\.|.)