Description
^(?!common:)(?:([^\s\n]+)\s+){2}
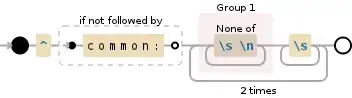
This regular expression will do the following:
- Skips the first line that starts with
common:
- Places into capture group 1 the value in the second column
- Is scalable in that the desired column can be controlled by changing the number in
{2} at the end
Example
Live Demo
https://regex101.com/r/rX1dL1/2
Sample text
common: "mortalkombat_sonia_rules_abc," player: "Mortal Kombat," 22-May-22
Test1 Test2 Type1 Type2 Type3 X Y HOR1 VER1 Data1 Error1
r1107 ab-1 abcr0201 222 22 -222 -22 -222 -22 2 2 Testing
r1106 ab-2 abcr0201 222 22 -222 -22 -222 -22 2 2 Testing
c377 ab-3 abcf0402 222 2 -222 -22 -222 -22 2 2 Testing
r632 ab-4 abcd0402 222 22 -222 -22 -222 -22 2 2 Testing
Sample Matches
MATCH 1
1. [87-92] `Test2`
MATCH 2
1. [176-180] `ab-1`
MATCH 3
1. [257-261] `ab-2`
MATCH 4
1. [338-342] `ab-3`
MATCH 5
1. [419-423] `ab-4`
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
^ the beginning of a "line"
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
common: 'common:'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture (2 times):
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^\s\n]+ any character except: whitespace (\n,
\r, \t, \f, and " "), '\n' (newline)
(1 or more times (matching the most
amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
\s+ whitespace (\n, \r, \t, \f, and " ") (1
or more times (matching the most amount
possible))
----------------------------------------------------------------------
){2} end of grouping
----------------------------------------------------------------------