I joined the party late, but I brought a new solution/insight using Pipeline():
- sub-pipeline containing your model (regression/classifier) as a single component
- main pipeline made of routine components:
- pre-processing component e.g., scaler, dimension reduction, etc.
- your refitted
GridSearchCV(regressor, param) with desired/best params for your model (Note: don't forget to refit=True) based on @Vivek Kumar remark ref
#build an end-to-end pipeline, and supply the data into a regression model and train and fit within the main pipeline.
#It avoids leaking the test\val-set into the train-set
# Create the sub-pipeline
#create and train the sub-pipeline
from sklearn.linear_model import SGDRegressor
from sklearn.compose import TransformedTargetRegressor
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
sgd_subpipeline = Pipeline(steps=[#('scaler', MinMaxScaler()), # better to not rescale internally
('SGD', SGDRegressor(random_state=0)),
])
# Define the hyperparameter grid
param_grid = {
'SGD__loss': ['squared_error', 'epsilon_insensitive', 'squared_epsilon_insensitive', 'huber'],
'SGD__penalty': ['l2', 'l1', 'elasticnet'],
'SGD__alpha': [0.0001, 0.001, 0.01],
'SGD__l1_ratio': [0.15, 0.25, 0.5]
}
# Perform grid search
grid_search = GridSearchCV(sgd_subpipeline, param_grid, cv=5, n_jobs=-1, verbose=True, refit=True)
grid_search.fit(X_train, y_train)
# Get the best model
best_sgd_reg = grid_search.best_estimator_
# Print the best hyperparameters
print('=========================================[Best Hyperparameters info]=====================================')
print(grid_search.best_params_)
# summarize best
print('Best MAE: %.3f' % grid_search.best_score_)
print('Best Config: %s' % grid_search.best_params_)
print('==========================================================================================================')
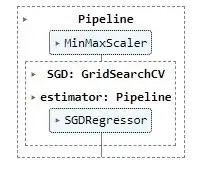
# Create the main pipeline by chaining refitted GridSerachCV sub-pipeline
sgd_pipeline = Pipeline(steps=[('scaler', MinMaxScaler()), # better to rescale externally
('SGD', grid_search),
])
# Fit the best model on the training data within pipeline (like fit any model/transformer): pipe.fit(traindf[features], traindf[labels]) #X, y
sgd_pipeline.fit(X_train, y_train)
#--------------------------------------------------------------
# Displaying a Pipeline with a Preprocessing Step and Regression
from sklearn import set_config
set_config(display="text")
Alternatively, you can use TransformedTargetRegressor (specifically if you need to descale y as @mloning
commented here) and chain this component, including your regression model ref.
Note:
- you don't need to set
transform argument unless you need descaling; please then check to related posts 1, 2, 3, 4, its score
- Pay attention to this remark about not scaling here since:
... With scaling y you actually lose your units....
- Here, It is recommended to:
... Do the transformation outside the pipeline. ...
#build an end-to-end pipeline, and supply the data into a regression model and train and fit within main pipeline.
#It avoids leaking the test\val-set into the train-set
# Create the sub-pipeline
from sklearn.linear_model import SGDRegressor
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
sgd_subpipeline = Pipeline(steps=[#('scaler', MinMaxScaler()), # better to not rescale internally
('SGD', SGDRegressor(random_state=0)),
])
# Define the hyperparameter grid
param_grid = {
'SGD__loss': ['squared_error', 'epsilon_insensitive', 'squared_epsilon_insensitive', 'huber'],
'SGD__penalty': ['l2', 'l1', 'elasticnet'],
'SGD__alpha': [0.0001, 0.001, 0.01],
'SGD__l1_ratio': [0.15, 0.25, 0.5]
}
# Perform grid search
grid_search = GridSearchCV(sgd_subpipeline, param_grid, cv=5, n_jobs=-1, verbose=True, refit=True)
grid_search.fit(X_train, y_train)
# Get the best model
best_sgd_reg = grid_search.best_estimator_
# Print the best hyperparameters
print('=========================================[Best Hyperparameters info]=====================================')
print(grid_search.best_params_)
# summarize best
print('Best MAE: %.3f' % grid_search.best_score_)
print('Best Config: %s' % grid_search.best_params_)
print('==========================================================================================================')
# Create the main pipeline using sub-pipeline made of TransformedTargetRegressor component
from sklearn.compose import TransformedTargetRegressor
TTR_sgd_pipeline = Pipeline(steps=[('scaler', MinMaxScaler()), # better to rescale externally
#('SGD', SGDRegressor()),
('TTR', TransformedTargetRegressor(regressor= grid_search, #SGDRegressor(),
#transformer=MinMaxScaler(),
#func=np.log,
#inverse_func=np.exp,
check_inverse=False))
])
# Fit the best model on the training data within pipeline (like fit any model/transformer): pipe.fit(traindf[features], traindf[labels]) #X, y
#best_sgd_pipeline.fit(X_train, y_train)
TTR_sgd_pipeline.fit(X_train, y_train)
#--------------------------------------------------------------
# Displaying a Pipeline with a Preprocessing Step and Regression
from sklearn import set_config
set_config(display="diagram")
