Use dataset[~dataset['title'].str.contains('word')] where the ~ operator takes care of the not in part of the procedure.
Example: Combining the powers of PowerBI and Python
Lets look at a made-up example of a dataset with good, bad or mediocre movies of some category and a column with an ID . If you take a look at the post How to make a reproducible data sample in PowerBI using Python? you can see how to insert a sample dataset in PowerBI using Python. And the post Power BI: Using Python on multiple tables in the Query Editor will show you alle the details of the procedure that follows here:
If you use the PowerQuery Editor toinsert a python snippet like this:
# 'dataset' holds the input data for this script
import pandas as pd
df_dataset = pd.DataFrame({'title': {0: 'bad movie',
1: 'mediocre movie',
2: 'bad movie',
3: 'bad movie',
4: 'good movie',
5: 'bad movie',
6: 'bad movie',
7: 'mediocre movie'},
'category': {0: 'drama',
1: 'comedy',
2: 'drama',
3: 'comedy',
4: 'action',
5: 'comedy',
6: 'drama',
7: 'comedy'},
'ID': {0: 32, 1: 46, 2: 96, 3: 25, 4: 83, 5: 78, 6: 36, 7: 96}})
... you'll end up wiht a table like this:
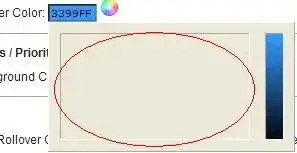
Now, inserting a new python snippet like this:
df_notbad = dataset[~dataset['title'].str.contains('bad')]
... will give you a dataset where all rows with 'bad' are removed:
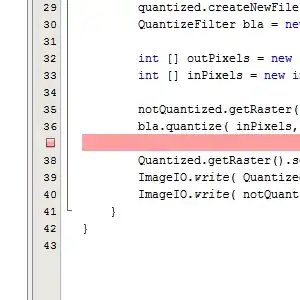
You will have to look at the linked resources to sort out all the details, but please don't hesitate to let me know if some of the details are unclear!

