A spreadsheet cannot do it as easily as with SQL, but here are two solutions.
Method 1 - Pivot Table
Make sure the first row of the column contains a label, for example Color. In the next column, set the label to Count. Enter a count of 1 for all colors.
Color Count
red 1
green 1
red 1
Then, select the two columns and go to Data -> Pivot Table -> Create. Drag Color to Row Fields, and drag Count to Data Fields.
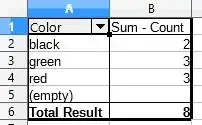
Method 2 - Filter
- Copy the column data, and paste into column A of a new sheet.
- Go to Data -> More Filters -> Standard Filter.
- Change
Field Name to - none -. Expand Options and check No duplicates. Press OK.
- In B1, enter the formula
=COUNTIF($Sheet1.G1:G100,"="&A1). Change "G" to the column you used on Sheet 1.
- Drag the formula down.
Links for getting distinct values are at https://stackoverflow.com/a/38286032/5100564.
