But how is this possible?
Basically, a program performs OCR on the input file and then it places an invisible layer of text over the picture. Alternatively, it might also place a visible layer of text under the picture, giving the same effect.
When you select something, the picture doesn't matter because the text layer gets selected.
how can this be created?
There are several ways. Given that Acrobat has already been suggested, I will add some free options (and luckily you are not forced to have Windows to use them).
PDF-XChange Viewer
This is a native Windows program by Tracker Software. The freeware version runs fine under Wine if you use the 32-bit edition in a 32-bit prefix, therefore you can use it on Windows, macOS and Linux. In the last two cases, you would need PlayOnMac or PlayOnLinux respectively.
Here's a picture from this answer I left on Ask Ubuntu:
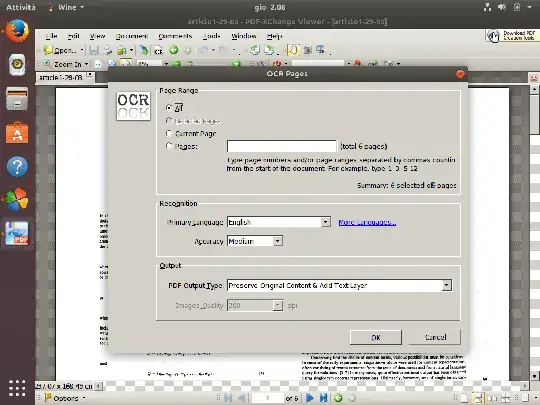
OCRmyPDF
This is a multiplatform program written in Python, based on Ghostscript, Tesseract and Unpaper. From the docs:
What OCRmyPDF does
OCRmyPDF analyzes each page of a PDF to determine the colorspace and
resolution (DPI) needed to capture all of the information on that page
without losing content. It uses Ghostscript to rasterize the page, and
then performs on OCR on the rasterized image to create an OCR “layer”.
The layer is then grafted back onto the original PDF.
It can be easily installed on Debian and Ubuntu derivatives:
apt-get install ocrmypdf
Or on macOS:
brew tap jbarlow83/ocrmypdf
brew install ocrmypdf
On Windows you would need to use the Docker image. See the official docs for details.
Usage is very simple and I suggest you use the optional -d (deskew) and -c (clean) parameters for better results. It will straighten every page and clean up small dots/imperfections before running the OCR process.
You can (and should) provide the language with -l.
Here's an example taken from this skewed document written in Italian:
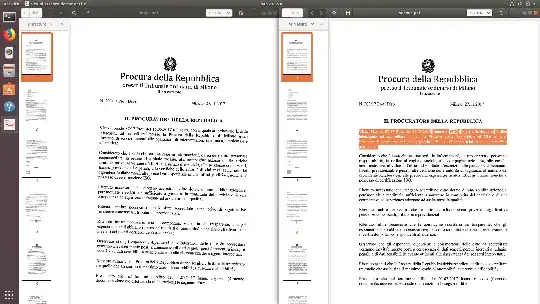
The command I used was:
ocrmypdf -l ita -d -c input.pdf output.pdf
Online tools
There are a few online tools that do the same. Notable, PDF24 hosts a free web-based version of OCRmyPDF that can be used without limitations.
See also:


