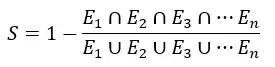I've generated some plots with the below code:
#Remove group label from the dataframe
data_just_feats <- data[ , -which(names(data) %in% c("Group"))]
Pca Plot
plot_1 <- autoplot(prcomp(data_just_feats), data = data, colour = 'Group', size = 0.001, frame = TRUE, frame.type = "norm") +
scale_color_manual(values=c(col.5, col.4, col.3)) +
scale_fill_manual(values= c(col.5, col.4, col.3)) +
theme(axis.line= element_line())
plot_1
Which gives the following:

But what I'd really like is the % overlap of the ellipses?
I'm a bit lost of where to go as the PCA is generated in the plot and to the best of my knowledge the ellipse values don't exist outside of the plot itself.
(R Studio)