To print a XHTML into a PDF on Windows we can use MS Edge but first need to set the page size by edit the style.
For the given example we need to use a find and replace the start of the <style> section, to match the content definition.
<meta content="width=354, height=581" .....>
<style>
this can easily be done with "fart-it" or any find and replace so for example:
fart199b page0490.xhtml "<style>" "<style> @media print { @page { margin: 0; size: 354px 581px ; } body { margin: 0; } }"
Once that is done we can run:
"C:\Program Files\Microsoft\Edge\Application\msedge.exe" --headless=old --print-to-pdf="%cd%\page0490.pdf" --no-pdf-header-footer "%CD%\page0490.xhtml"
The result will be a PDF of correct proportions.
137397 bytes written to file ...OEBPS\page0490.pdf
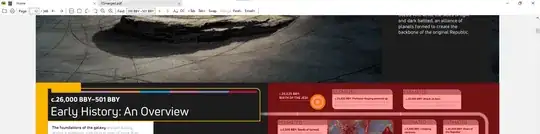
However if you run without the correct relative fonts. You will get wrong results like this:
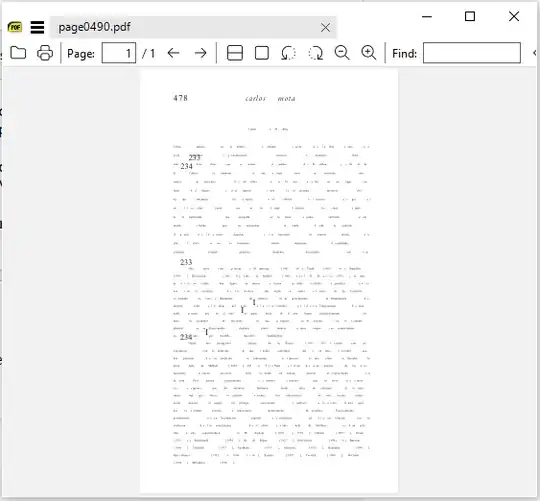
But if the fonts are correct you can expect a reasonable result.
To run for a collection of files we need to wrap the 2 lines a for loop.
Try-1-9.CMD as a single loop we can only run each place of digits but you can loop loops if you wish.
For /L %%c in (1,1,9) do (
fart199b page000%%c.xhtml "<style>" "<style> @media print { @page { margin: 0; size: 354px 581px ; } body { margin: 0; } }"
timeout 2
"C:\Program Files\Microsoft\Edge\Application\msedge.exe" --headless=old --print-to-pdf="%cd%\page000%%c.pdf" --no-pdf-header-footer "%CD%\page000%%c.xhtml"
)
Try-10-99.cmd
For /L %%c in (10,1,99) do (
fart199b page00%%c.xhtml "<style>" "<style> @media print { @page { margin: 0; size: 354px 581px ; } body { margin: 0; } }"
timeout 2
"C:\Program Files\Microsoft\Edge\Application\msedge.exe" --headless=old --print-to-pdf="%cd%\page00%%c.pdf" --no-pdf-header-footer "%CD%\page00%%c.xhtml"
)
etc. for 100-999 and 1000-9999 edit by add digit and remove 0 or set last number. There is a "trick" to use a set variable with leading zeros and truncate to a set number of characters. But that is a different question.
I suggest you try-1-9 just to check it is functioning well before run 10-99 etc. You could reduce the timeout to 1 but it is there to ensure the Find and replace is finished before the print to pdf.
Faster would be just do the find and replace and check. Then without any delay run a batch of printing. But watch task manager to ensure there are no problems with memory, as I have heard some users complain of large fast batches failing.
Later Edit
In a different production run I found a few oddities with page fitting and need to address the way MS Edge auto resizes pages. The best method then became much longer.
@echo off & REM are remarks so lines can be deleted in a work copy once tested, The MAIN function is latter at :SKIPCOPY
REM designed to be run in an UNZIPPED source.epub OEBPS folder can use windows MS Edge or Better Chrome-headless-shell
REM current 32bit version (change both those 32 to 64 if you wish) of headless shell is at
REM https://storage.googleapis.com/chrome-for-testing-public/131.0.6778.108/win32/chrome-headless-shell-win32.zip
REM I suggest copy the chromium files AS A SUBFOLDER into the c:\WORKING folder and the source\OEBPS folder can be there too
REM NOTE here requires running FART-IT version 199b from https://sourceforge.net/projects/fart-it/files/fart-it/1.99b/
REM unpack to one or other paths and ensure they are on PATH OR Current Directory OR correctly prefixed with their path
set "FindReplace=%CD%\fart199b.exe"
if not exist %FindReplace% exit/b
REM Static %VALUES%
REM long filenames in commands can cause problems downstream so copy files to short temp path do not add \ on the end
REM output will be in a subfolder "output" you can change the name for different runs
REM NOTE the css fonts and images subfolder need to be subfolders of WORKDIR but pages copied from the source folder
set "WORKDIR=c:\workdir"
set "OUT=output"
if not exist "%WORKDIR%%OUT%" md "%WORKDIR%%OUT%"
REM On Windows we can use MS Edge or Chrome-headless-shell which could be in the workdir
REM set "XHTML2PDF=C:\Program Files\Microsoft\Edge\Application\msedge.exe"
set "XHTML2PDF=%WORKDIR%\chrome-headless-shell\chrome-headless-shell.exe"
REM For smaller (less accesibility featured) files we add --disable-pdf-tagging
REM IMPORTANT For "msedge.exe" add in --headless=old .
set "ARGS= --disable-pdf-tagging=true --run-all-compositor-stages-before-draw --virtual-time-budget=10000 --no-pdf-header-footer"
REM NOTE this part be stupidly slow if like my example has 2,700+ font Files which could be better / faster copied from the source direct
REM If css, fonts and images exist as subfolders of WORKDIR from unpacking with OEBPS or a prior run remove rem on next line
REM goto SKIPCOPY
if not exist "%WORKDIR%\css" md "%WORKDIR%\css"
copy /y "css*.*" "%WORKDIR%\css"
if not exist "%WORKDIR%\fonts" md "%WORKDIR%\fonts"
copy /y "fonts*.*" "%WORKDIR%\fonts"
if not exist "%WORKDIR%\images" md "%WORKDIR%\images"
copy /y "images*.*" "%WORKDIR%\images"
:SKIPCOPY
REM edit to last page Number eg "PAGES=301" HOWEVER start with a small run of say 10-20
set "PAGES=364"
REM start is normally page 2 (after a cover page) but if needing to start after a "test run" of 20 can be changed to say 21
set "START=2"
REM "DIGITS=3" expands to Page### match the numeri's from e.g. "page002.xhtml"
set "DIGITS=3"
REM WIDTH and HEIGHT are the "Rounded" whole Number pixel (px) values expected to be constant for all PAGES check dimensions in images folder
REM Cover may be different so obtain the X Y values from 0002.xhtml, for other sizes change and run ranges accordingly
REM Tech note these are not final PDF page units which will usually be 75% (72pt/96px) eg 1600px 2000px will become /MediaBox[0 0 1200 1500]
REM If a different size is needed you may need to alter scale or crop when merging / bookmarking pages in a separate process.
REM Integers divisible by 4 are best for control but may then have thin white pixel margins and thus for "spreads" needing a minute crop or trim later.
set "XWIDTH=1610.26px"
set "WIDTH=1610px"
set "YHEIGHT=1923.75px"
set "HEIGHT=1924px"
setlocal ENABLEDELAYEDEXPANSION
REM COVER ONLY note manually change "Cover.PDF" to "Page001.PDF" etc as desired later for merging. To "skip cover" on any other runs
REM remove REM on next line where skip will be the %START% value
REM goto SKIPCOVER
copy "Cover.xhtml" "%WORKDIR%\cover.xhtml"
"%FindReplace%" "%WORKDIR%\cover.xhtml" "<style>" "<style> @media print { @page { margin: 0; size: %WIDTH% %HEIGHT% ; } body { margin: 0; } }" > nul
REM there are other places that also MAY need to be forced to match those values 1= <body style=... 2= <div class="PageContainer"
REM for example if they are width:%XWIDTH%;height:%YHEIGHT%; these need to become "width:%WIDTH%;%HEIGHT%;"
"%FindReplace%" "%WORKDIR%\cover.xhtml" "width:%XWIDTH%;height:%YHEIGHT%;" "width:%WIDTH%;height:%HEIGHT%;" > nul
REM if pages are undersized it may also need the following "bottom and right" setting either here and / or below in pages
REM "%FindReplace%" "%WORKDIR%\cover.xhtml" "position:absolute;top:0px;left:0px;" "position:absolute;top:0px;bottom:0px;right:0px;left:0px;" > nul
REM For speed use Chrome-headless-shell it may seem slow with first file but should pick up speed.
"%XHTML2PDF%" "%ARGS%" --print-to-pdf="%WORKDIR%%OUT%\cover.pdf" "%WORKDIR%\cover.xhtml"
We can build a list of "done" files as filelist.txt can help if used as a basic command file such as rename mergelist.cmd or edit as desired
echo "%WORKDIR%%OUT%\cover.pdf" >"%WORKDIR%\mergelist.txt"
:SKIPCOVER
For /L %%c in (%START%,1,%PAGES%) do (
set "String=0000%%c"
set "Number=!String:~-%DIGITS%!"
echo Number !Number! started
REM set a timeout to allow for catch-up or resources such as depleted memory / file handles may lead to fail
Timeout 1 > nul
REM error abort to avoid build wrong size blanks
if not exist "page!Number!.xhtml" exit /b
copy "page!Number!.xhtml" "%WORKDIR%\page!Number!.xhtml"
"%FindReplace%" "%WORKDIR%\page!Number!.xhtml" "<style>" "<style> @media print { @page { margin: 0; size: %WIDTH% %HEIGHT% ; } body { margin: 0; } }" > nul
"%FindReplace%" "%WORKDIR%\page!Number!.xhtml" "width:%XWIDTH%;height:%YHEIGHT%;" "width:%WIDTH%;height:%HEIGHT%;" > nul
REM may also need "%FindReplace%" "%WORKDIR%\page!Number!.xhtml" "position:absolute;top:0px;left:0px;" "position:absolute;top:0px;bottom:0px;right:0px;left:0px;" > nul
"%XHTML2PDF%" "%ARGS%" --print-to-pdf="%WORKDIR%%OUT%\page!Number!.pdf" "%WORKDIR%\page!Number!.xhtml"
echo "%WORKDIR%%OUT%\page!Number!.pdf" >>"%WORKDIR%\mergelist.txt"
echo Number !Number! done & echo/
)
GS is good for a Merge
Apps\pdf\GS\gs10040\bin\gs -sDEVICE=pdfwrite -oc:\workdir\GSmerged.pdf @c:\workdir\mergelist.txt
And if done right should look seamless for "spreads" with searchable text. File size will be a bit bigger so a 100 MB.ePub became a 105 MB.pdf!