I have summarize the answers and comments, and I have came up with 2 main solutions. The first solution is a safest but it is kind of complex, the third one, however, sticks to the origin question:
Solution 1: Creating a LVM Logical Volume across several flash drives
Thank you for @GlennWillen for the comment for the link and the reminder.
Note: The following steps are copied from the website
Step 1 – Create a Partition on each of the USB Flash Drives
Before starting, remember to plug all four usbs in
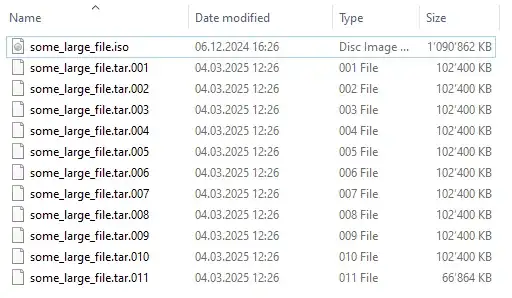
$ sudo fdisk /dev/sdb
Welcome to fdisk (util-linux 2.37.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): p
Disk /dev/sdb: 1.87 GiB, 2002780160 bytes, 3911680 sectors
Disk model: Flash Disk
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x6a5f5bac
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-3911679, default 2048):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-3911679, default 3911679):
Created a new partition 1 of type 'Linux' and of size 1.9 GiB.
Command (m for help): p
Disk /dev/sdb: 1.87 GiB, 2002780160 bytes, 3911680 sectors
Disk model: Flash Disk
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x6a5f5bac
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 3911679 3909632 1.9G 83 Linux
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
Step 2 – Create the LVM Physical Volumes (PVs)
Once the drives are ready, we will create the PVs on the USB flash drives. There is a 1:1 mapping between the PVs and the partitions.
Since each USB flash drive was configured to have one partition that spans the entire disk, no partition devices (e.g. /dev/sdb1) will appear. We can then create the PVs on the “raw” device itself:
$ sudo pvcreate /dev/sdb /dev/sdc /dev/sdd /dev/sde
Physical volume "/dev/sdb" successfully created.
Physical volume "/dev/sdc" successfully created.
Physical volume "/dev/sdd" successfully created.
Physical volume "/dev/sde" successfully created.
Step 3 – Create the LVM Volume Group (VG) using the PVs
In this step, we will group the PVs together into one VG. This layer is important as it abstracts away the physical disks (represented by their corresponding PVs), enabling some of the key benefits of using LVM, such as resizing by adding/removing physical disks while the volume is in use.
$ sudo vgcreate vg00 /dev/sdb /dev/sdc /dev/sdd /dev/sde
Volume group "vg00" successfully created
Step 4 – Create the LVM Logical Volume (LV) using the VG
For the final LVM step, we will create a logical volume that uses the VG vg00 that we created in the previous step:
$ sudo lvcreate -n my_volume -l 100%FREE vg00
Logical volume "lv01" created.
Step 5 – Create the File System and Mount it
The LVM Logical Volume behaves similarly to a block device – we need to install a filesystem and mount it before we can use it:
$ sudo mkfs.ext4 /dev/mapper/vg00-lv01
$ sudo mount -t ext4 /dev/mapper/vg00-lv01 <PATH TO MOUNT POINT>
Solution 2: Split the file into half and re-combine it when using it.
Thank you for @vidarlo for the answer and the suggestion.
Use split to split the files:
split -b 60G filename
Note that -b is the size byte per output file
Will give you filename01 and filename02.
To restore original simply do:
cat filename01 filename02 > filename
Solution 3: Using RAID technology
RAID (Redundant Array of Independent Disks) is a technology used to combine multiple storage devices (like hard drives or USB flash drives) into a single logical unit. It can provide performance benefits, redundancy, or both, depending on the RAID level used.
Extended solution: Zip the folder and store it by parts
Thank you for @velvet for the answer for the answer and suggestion
Another solution is to use 7-zip to split the archive file and create a .tar file.
Use 7z to zip the file to chunks of 100MB (or whatever you want)
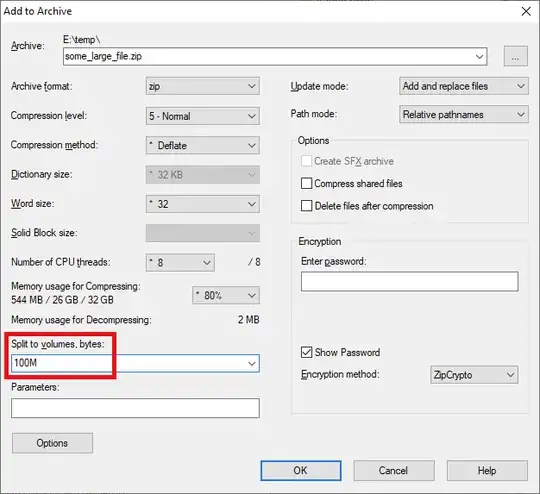
Result