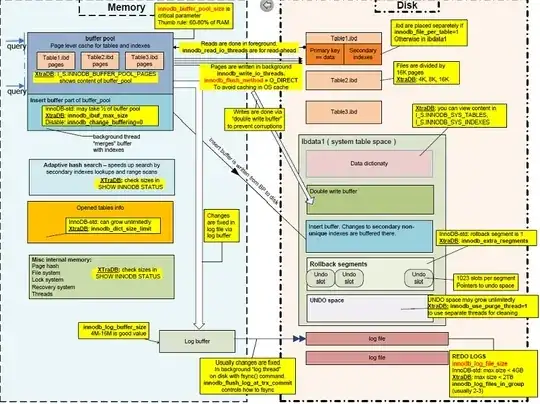
Filesystem errors, or even block level errors, aren't the sort of the items extensive tested or accounted for by the implementation of MyISAM or Innodb. While some detection may happen when they are written there's a large assumption that what once its written without an error returned, it is correct. Checksums exist and are checked on read, but the error recovery path on on pages/rows that fail checksum I don't think have been thought through fully.
I suspect the right risk mitigation strategy for this (and a few other forms of server failure) is to run a replication slave on a different filesystem, and as a DR, keep binary logs and a logical SQL snapshot dump. This way you don't need to rely on tools that might be able to work around some forms of failure with dataloss.