This is a partial answer with partial automation. It may stop working in the future if Google chooses to crack down on automated access to Google Takeout. Features currently supported in this answer:
+---------------------------------------------+------------+---------------------+
| Automation Feature | Automated? | Supported Platforms |
+---------------------------------------------+------------+---------------------+
| Google Account log-in | No | |
| Get cookies from Mozilla Firefox | Yes | Linux |
| Get cookies from Google Chrome | Yes | Linux, macOS |
| Request archive creation | No | |
| Schedule archive creation | Kinda | Takeout website |
| Check if archive is created | No | |
| Get archive list | Broken | Cross-platform |
| Download all archive files | Broken | Linux, macOS |
| Encrypt downloaded archive files | No | |
| Upload downloaded archive files to Dropbox | No | |
| Upload downloaded archive files to AWS S3 | No | |
+---------------------------------------------+------------+---------------------+
Firstly, a cloud-to-cloud solution can't really work because there is no interface between Google Takeout and any known object storage provider. You've got to process the backup files on your own machine (which could be hosted in the public cloud, if you wanted) before sending them off to your object storage provider.
Secondly, as there is no Google Takeout API, an automation script needs to pretend to be a user with a browser to walk through the Google Takeout archive creation and download flow.
Automation Features
Google Account log-in
This is not yet automated. The script would need to pretend to be a browser and navigate possible hurdles such as two-factor authentication, CAPTCHAs, and other increased security screening.
Get cookies from Mozilla Firefox
I have a script for Linux users to grab the Google Takeout cookies from Mozilla Firefox and export them as environment variables. For this to work, the default/active profile must have visited https://takeout.google.com while logged in.
As a one-liner:
cookie_jar_path=$(mktemp) ; source_path=$(mktemp) ; firefox_profile=$(cat "$HOME/.mozilla/firefox/profiles.ini" | awk -v RS="" '{ if($1 ~ /^\[Install[0-9A-F]+\]/) { print } }' | sed -nr 's/^Default=(.*)$/\1/p' | head -1) ; cp "$HOME/.mozilla/firefox/$firefox_profile/cookies.sqlite" "$cookie_jar_path" ; sqlite3 "$cookie_jar_path" "SELECT name,value FROM moz_cookies WHERE host LIKE '%.google.com' AND (name LIKE 'SID' OR name LIKE 'HSID' OR name LIKE 'SSID' OR (name LIKE 'OSID' AND host LIKE 'takeout.google.com')) AND originAttributes LIKE '^userContextId=1' ORDER BY creationTime ASC;" | sed -e 's/|/=/' -e 's/^/export /' | tee "$source_path" ; source "$source_path" ; rm -f "$source_path" ; rm -f "$cookie_jar_path"
As a prettier Bash script:
#!/bin/bash
# Extract Google Takeout cookies from Mozilla Firefox and export them as envvars
#
# The browser must have visited https://takeout.google.com as an authenticated user.
Warn the user if they didn't run the script with source
[[ "${BASH_SOURCE[0]}" == "${0}" ]] &&
echo 'WARNING: You should source this script to ensure the resulting environment variables get set.'
cookie_jar_path=$(mktemp)
source_path=$(mktemp)
In case the cookie database is locked, copy the database to a temporary file.
Edit the $firefox_profile variable below to select a specific Firefox profile.
firefox_profile=$(
cat "$HOME/.mozilla/firefox/profiles.ini" |
awk -v RS="" '{
if($1 ~ /^[Install[0-9A-F]+]/) {
print
}
}' |
sed -nr 's/^Default=(.*)$/\1/p' |
head -1
)
cp "$HOME/.mozilla/firefox/$firefox_profile/cookies.sqlite" "$cookie_jar_path"
Get the cookies from the database
sqlite3 "$cookie_jar_path"
"SELECT name,value
FROM moz_cookies
WHERE host LIKE '%.google.com'
AND (
name LIKE 'SID' OR
name LIKE 'HSID' OR
name LIKE 'SSID' OR
(name LIKE 'OSID' AND host LIKE 'takeout.google.com')
) AND
originAttributes LIKE '^userContextId=1'
ORDER BY creationTime ASC;" |
# Reformat the output into Bash exports
sed -e 's/|/=/' -e 's/^/export /' |
# Save the output into a temporary file
tee "$source_path"
Load the cookie values into environment variables
source "$source_path"
Clean up
rm -f "$source_path"
rm -f "$cookie_jar_path"
Get cookies from Google Chrome
I have a script for Linux and possibly macOS users to grab the Google Takeout cookies from Google Chrome and export them as environment variables. The script works on the assumption that Python 3 venv is available and the Default Chrome profile visited https://takeout.google.com while logged in.
As a one-liner:
if [ ! -d "$venv_path" ] ; then venv_path=$(mktemp -d) ; fi ; if [ ! -f "${venv_path}/bin/activate" ] ; then python3 -m venv "$venv_path" ; fi ; source "${venv_path}/bin/activate" ; python3 -c 'import pycookiecheat, dbus' ; if [ $? -ne 0 ] ; then pip3 install git+https://github.com/n8henrie/pycookiecheat@dev dbus-python ; fi ; source_path=$(mktemp) ; python3 -c 'import pycookiecheat, json; cookies = pycookiecheat.chrome_cookies("https://takeout.google.com") ; [print("export %s=%s;" % (key, cookies[key])) for key in ["SID", "HSID", "SSID", "OSID"]]' | tee "$source_path" ; source "$source_path" ; rm -f "$source_path" ; deactivate
As a prettier Bash script:
#!/bin/bash
# Extract Google Takeout cookies from Google Chrome and export them as envvars
#
# The browser must have visited https://takeout.google.com as an authenticated user.
Warn the user if they didn't run the script with source
[[ "${BASH_SOURCE[0]}" == "${0}" ]] &&
echo 'WARNING: You should source this script to ensure the resulting environment variables get set.'
Create a path for the Chrome cookie extraction library
if [ ! -d "$venv_path" ]
then
venv_path=$(mktemp -d)
fi
Create a Python 3 venv, if it doesn't already exist
if [ ! -f "${venv_path}/bin/activate" ]
then
python3 -m venv "$venv_path"
fi
Enter the Python virtual environment
source "${venv_path}/bin/activate"
Install dependencies, if they are not already installed
python3 -c 'import pycookiecheat, dbus'
if [ $? -ne 0 ]
then
pip3 install git+https://github.com/n8henrie/pycookiecheat@dev dbus-python
fi
Get the cookies from the database
source_path=$(mktemp)
read -r -d '' code << EOL
import pycookiecheat, json
cookies = pycookiecheat.chrome_cookies("https://takeout.google.com")
for key in ["SID", "HSID", "SSID", "OSID"]:
print("export %s=%s" % (key, cookies[key]))
EOL
python3 -c "$code" | tee "$source_path"
Clean up
source "$source_path"
rm -f "$source_path"
deactivate
[[ "${BASH_SOURCE[0]}" == "${0}" ]] && rm -rf "$venv_path"
Clean up downloaded files:
rm -rf "$venv_path"
Request archive creation
This is not yet automated. The script would need to fill out the Google Takeout form and then submit it.
Schedule archive creation
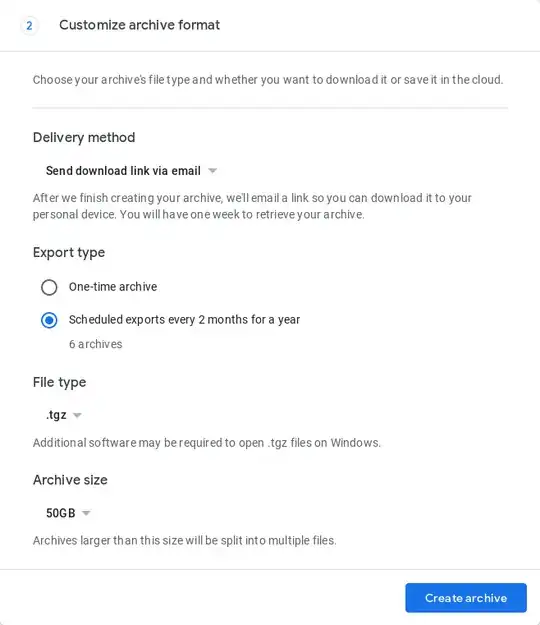
There is no fully automated way to do this yet, but in May 2019, Google Takeout introduced a feature that automates the creation of 1 backup every 2 months for 1 year (6 backups total). This has to be done in the browser at https://takeout.google.com while filling out the archive request form:
Check if archive is created
This is not yet automated. If an archive has been created, Google sometimes sends an email to the user's Gmail inbox, but in my testing, this doesn't always happen for reasons unknown.
The only other way to check if an archive has been created is by polling Google Takeout periodically.
Get archive list
This section is currently broken.
Google stopped revealing the archive download links on the Takeout download page and has implemented a secure token that limits the download link retrieval for each archive to a maximum of 5 times.
I have a command to do this, assuming that the cookies have been set as environment variables in the "Get cookies" section above:
curl -sL -H "Cookie: SID=${SID}; HSID=${HSID}; SSID=${SSID}; OSID=${OSID};" \
'https://takeout.google.com/settings/takeout/downloads' |
grep -Po '(?<=")https://storage.cloud.google.com/[^"]+(?=")' |
awk '!x[$0]++'
The output is a line-delimited list of URLs that lead to downloads of all available archives.
It's parsed from HTML with regex.
Download all archive files
This section is currently broken.
Google stopped revealing the archive download links on the Takeout download page and has implemented a secure token that limits the download link retrieval for each archive to a maximum of 5 times.
Here is the code in Bash to get the URLs of the archive files and download them all, assuming that the cookies have been set as environment variables in the "Get cookies" section above:
curl -sL -H "Cookie: SID=${SID}; HSID=${HSID}; SSID=${SSID}; OSID=${OSID};" \
'https://takeout.google.com/settings/takeout/downloads' |
grep -Po '(?<=")https://storage.cloud.google.com/[^"]+(?=")' |
awk '!x[$0]++' |
xargs -n1 -P1 -I{} curl -LOJ -C - -H "Cookie: SID=${SID}; HSID=${HSID}; SSID=${SSID}; OSID=${OSID};" {}
I've tested it on Linux, but the syntax should be compatible with macOS, too.
Explanation of each part:
curl command with authentication cookies:
curl -sL -H "Cookie: SID=${SID}; HSID=${HSID}; SSID=${SSID}; OSID=${OSID};" \
URL of the page that has the download links
'https://takeout.google.com/settings/takeout/downloads' |
Filter matches only download links
grep -Po '(?
Filter out duplicate links
awk '!x[$0]++' |
Download each file in the list, one by one:
xargs -n1 -P1 -I{} curl -LOJ -C - -H "Cookie: SID=${SID}; HSID=${HSID}; SSID=${SSID}; OSID=${OSID};" {}
Note: Parallelizing the downloads (changing -P1 to a higher number) is possible, but Google seems to throttle all but one of the connections.
Note: -C - skips files that already exist, but it might not successfully resume downloads for existing files.
Encrypt downloaded archive files
This is not automated. The implementation depends on how you like to encrypt your files, and the local disk space consumption must be doubled for each file you are encrypting.
Upload downloaded archive files to Dropbox
This is not yet automated.
Upload downloaded archive files to AWS S3
This is not yet automated, but it should simply be a matter of iterating over the list of downloaded files and running a command like:
aws s3 cp TAKEOUT_FILE "s3://MYBUCKET/Google Takeout/"
