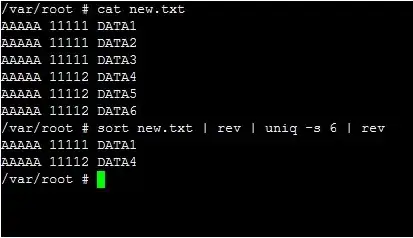
I've got a dataset that goes like this:
AAAAA 11111 Data1
AAAAA 11111 Data2
AAAAA 11111 Data3
AAAAA 11112 Data4
AAAAA 11112 Data5
AAAAA 11112 Data6
AAAAA 11112 Data7
AAAAA 11113 Data8
AAAAA 11114 Data9
And so on. I want to filter according to the 2nd field and then run a uniq to only pull the FIRST entry. In this case, I want the output to be:
AAAAA 11111 Data1
AAAAA 11112 Data4
AAAAA 11113 Data8
AAAAA 11114 Data9
This seems like it would be pretty easy, but the method is just slipping me. Any help?